What Are Large Language Models (LLMs) and How Are They Being Used
“Large Language Models”
A language model is a type of artificial intelligence model that is trained to predict the next word in a sequence of words. It does this by analyzing the text it has been trained on, and using that information to assign probabilities to each possible next word. This allows the model to understand the structure of natural language and generate text that is coherent and grammatically correct.
Language models are commonly used in applications such as speech recognition, machine translation, and natural language processing. They are also a crucial component of modern chatbots and virtual assistants, which use language models to understand and generate human-like responses to user input.
Types of Language Models
There are several different types of language models, each with its own strengths and weaknesses. Some of the most common include:
- Statistical language models, which use statistical algorithms to assign probabilities to possible next words based on the text they have been trained on. These models can handle large amounts of data, but may struggle with rare or out-of-vocabulary words.
- Neural language models, which use deep learning techniques to learn the relationships between words in a text. These models can handle large amounts of data and can often generate more coherent and natural-sounding text than statistical models.
- Rule-based language models, which use a set of pre-defined rules to generate text. These models can produce highly accurate and grammatically correct text, but may struggle with handling complex or unpredictable input.
How Are Language Models Built
To build a language model, data scientists typically start by collecting a large corpus of text, which can be sourced from a variety of sources such as books, articles, and websites. The text is then preprocessed to clean and normalize it, which typically involves tasks such as removing punctuation, converting all text to lowercase, and tokenizing it into individual words or phrases.
Once the data is ready, the language model is trained using a specific algorithm or set of algorithms. For example, a statistical language model might use a n-gram model, which assigns probabilities to sequences of n words (where n is a parameter of the model). A neural language model, on the other hand, might use a recurrent neural network (RNN), which processes the text in a sequential manner and learns the relationships between words as it goes.
After the model is trained, it can be evaluated on a held-out dataset to measure its performance. The performance of a language model is typically measured using metrics such as perplexity, which measures how well the model can predict the next word in a sequence, or BLEU score, which measures the overlap between the model’s generated text and a reference text.
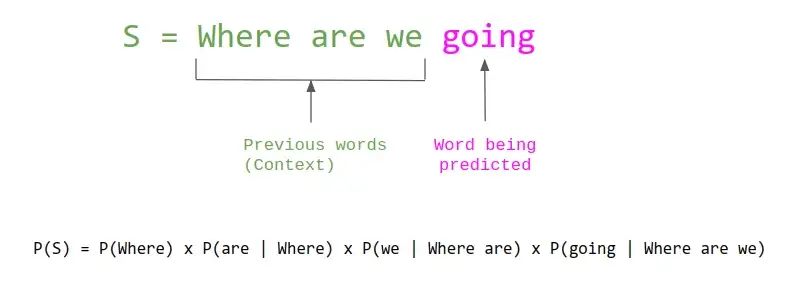
The probability of a sentence can be defined as the product of the probability of each word given the previous words
A Simple Example in R
Over a decade ago I built a small language model using the R Statistical Programming language. You can play with this simple model here:
https://analytica.shinyapps.io/NLPWordPrediction/
Examples of language models
- GPT-3 (Generative Pretrained Transformer 3): This is a large-scale language model developed by OpenAI. It uses deep learning algorithms and has been trained on a massive amount of text data, which allows it to generate human-like text. It is considered to be one of the most advanced language models currently available.
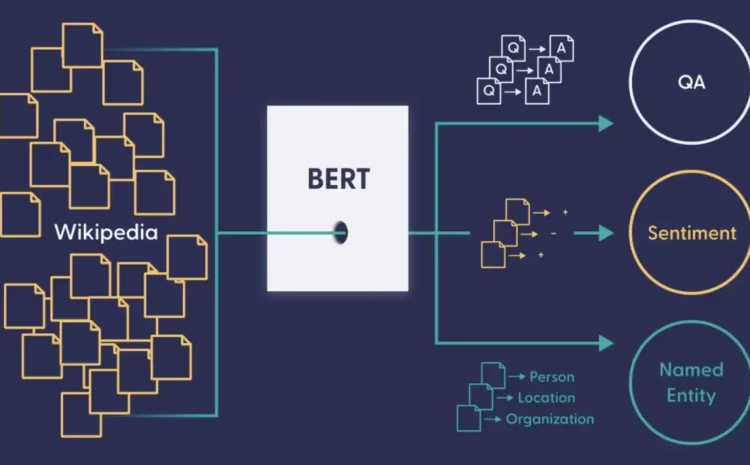
- BERT (Bidirectional Encoder Representations from Transformers): This is another large-scale language model developed by Google. It is trained to understand the context of words in a sentence, which allows it to perform well on tasks such as natural language understanding and language translation.
- ELMo (Embeddings from Language Models): This is a language model developed by researchers at the Allen Institute for Artificial Intelligence. It uses a combination of character-based and word-based models to generate contextualized word representations, which can be used for a variety of natural language processing tasks.
Complexity of Language Models
Language models can be complex because they often have to process large amounts of text data and learn to understand the nuances of human language. This requires a lot of computing power and sophisticated algorithms, which can make them difficult to develop and use. Additionally, because language is constantly evolving, language models must be regularly updated and retrained in order to stay accurate and effective.
The complexity of a language model is often determined by a number of factors, including the amount of text data used to train the model, the size of the model (measured in terms of the number of parameters), and the type of algorithms used to train the model.
For example, GPT-3 is considered to be one of the most complex language models currently available. It has 175 billion parameters, which means that it has 175 billion “knobs” that can be adjusted to fine-tune its performance. This allows it to generate highly realistic text, but it also makes it computationally expensive to train and use.
On the other hand, ELMo is a smaller language model with only about 30 million parameters. This means that it is not able to generate text as realistically as GPT-3, but it can be trained and used more efficiently.
Overall, the complexity of a language model depends on the specific tasks it is designed to perform and the trade-offs between performance and efficiency that are desired.
Uses of Language Models
Language models are being used in a wide range of applications where understanding and generating natural language is important.
- Natural language processing: Language models can be used to understand and generate human-like text, which allows them to be used for tasks such as language translation, text summarization, and question answering.
- Sentiment analysis: Language models can be trained to identify the sentiment (e.g. positive, negative, or neutral) of a piece of text, which can be useful for applications such as social media analysis and customer feedback analysis.
- Text generation: Language models can be used to generate new text based on a given input. For example, they can be used to generate personalized responses in chatbots, or to create new articles or stories based on a given topic.
- Speech recognition: Language models can be used to process and understand spoken language, which allows them to be used for tasks such as speech-to-text transcription and voice command recognition.
- Improving the accuracy of search engines: Language models can be used to better understand the context and meaning of the words and phrases used in search queries, which can help search engines return more relevant and accurate results.
- Improving customer service: Language models can be used in chatbots and other customer service systems to generate more natural and human-like responses to customer inquiries.
- Automated content creation: Language models can be used to generate articles, reports, and other written content automatically, which can save time and improve the efficiency of certain tasks.
- Improving the accessibility of digital content: Language models can be used to automatically generate audio versions of written content, which can make it more accessible to people with visual impairments or learning disabilities.
- Personalizing user experiences: Language models can be used to generate personalized recommendations and suggestions based on a user’s past interactions and preferences. This can help improve the user experience and make it more engaging and relevant.
Overall
language models are a crucial part of modern artificial intelligence and natural language processing. By understanding the structure of natural language, they enable applications such as speech recognition, machine translation, and chatbots to generate coherent and human-like responses to user input.
In conclusion, language models are powerful tools that are being used to understand and generate human-like text, and they have a wide range of applications in natural language processing and other fields. As these models continue to improve and become more sophisticated, they are likely to be used in even more ways in the future, potentially transforming how we interact with technology and enabling new capabilities and applications. It will be exciting to see how language models continue to evolve and what new possibilities they will enable in the coming years.
Read More blogs in AnalyticaDSS Blogs here : BLOGS
Read More blogs in Medium : Medium Blogs




