Unleash the Power of Functional Programming in R with the purrr Package
Introduction
Welcome to our comprehensive guide on harnessing the power of the purrr package in R for functional programming. If you’re keen on elevating your R skills, you’re in for a treat. Today, we’ll be delving into the wonders of the purrr package — a lifesaver for functional programming. With the avalanche of data we encounter nowadays, having the right tools for efficient data wrangling is paramount. If you’ve dabbled in R, you might’ve felt certain built-in functions lacking, especially when grappling with intricate operations.
This is where purrr strides in, offering a plethora of robust tools to fine-tune your code, making it not only clearer but also more sustainable.
Throughout this article, we’ll journey through the intricacies of the purrr package, elucidate its fundamental functions, and showcase its real-world applicability. We’ll also touch on how it can enrich your experience with R, making it more fruitful. By the time you reach the end, you’ll be well-versed in the magic of purrr and ready to wield its power in your data endeavors. Let’s embark on this insightful voyage into the realm of R and unravel the capabilities of the purrr package.
What is functional programming and why is it useful?
Functional programming isn’t merely a way to write code; it’s a philosophical shift that guides how we approach computation. By treating computation as the evaluation of mathematical functions, it foregoes changes to the state and avoids mutable data. Instead, it thrives on pure functions that take given inputs and produce predictable outputs, devoid of side effects. The outcome? Code that’s more modular, predictable, and test-friendly.
Now, if you’re working with R, particularly for data manipulation and analysis, functional programming can be a game-changer. It lets you create more coherent and succinct code, and here’s how:
- Enhanced Readability and Sustainability: Decomposing complex procedures into smaller, more digestible functions improves the understandability of your code. Plus, it’s easier to tweak as needed.
- Boosted Productivity: By steering clear of traps like global variables, which may lead to unforeseen behaviors and debugging headaches, functional programming saves time and frustration.
- Optimized Performance: Embracing functional programming could also enhance the efficiency of your code. It prompts the use of vectorized operations and cuts down on the necessity for explicit loops.
Eager to tap into these benefits? Read on! We’ll dive into the purrr package, an invaluable asset for adopting functional programming in R. Through its power, you can not only elevate your data manipulation and analysis routines but also bring more enjoyment and effectiveness to your programming journey.
Exploring the purrr package
Belonging to the tidyverse collection, the purrrpackage serves as R’s gateway to functional programming. It’s packed with dynamic functions crafted to ease tasks when working with lists and a variety of data structures. Adopting purrrensures that your data transformation, summarization, and manipulation processes benefit from a unified and logical syntax.
Let’s delve into what sets purrrapart:
- Uniformity in Function Naming: One of
purrrs’strengths is its organized naming structure, simplifying the task of recalling and employing its functions. - Proficiency with Complex Data Structures: Be it nested lists, data frames, or any layered data structure,
purrrstands out in its management capabilities. - Robust Error Management: Real-world data can be messy.
purrrlends a hand by equipping you with functions that elegantly tackle errors and unexpected scenarios. - Harmony with
tidyverseCompanions: A significant advantage ispurrrcompatibility with renownedtidyverseallies such asdplyr,tidyr, andggplot2. This cohesion allows for a smoother integration of functional programming into your prevailing data routines.
Keen to commence your purrrjourney? Simply fetch it from CRAN and initialize it in your R workspace.
install.packages("purrr")
library(purrr)In the next section, we will dive into the core functions provided by the purrr package and demonstrate their usage with practical examples.
Core functions in purrr
In this section, we will cover some of the most important and widely used functions in the purrr package, along with examples to demonstrate their usage.
A. The map() family
The map() family of functions is the heart of the purrr package. These functions allow you to apply a function to each element of a list or a vector and return the results in a specified format.
map(): Returns a list.map_lgl(): Returns a logical vector.map_int(): Returns an integer vector.map_dbl(): Returns a double vector.map_chr(): Returns a character vector.map_df(): Returns a data frame.
Example:
# Define a list of numbers
number_list <- list(1, 2, 3, 4)
# Square each number using map()
squared_numbers <- map(number_list, ~ .x^2)
print(squared_numbers)B. pmap()
The pmap() function is used to apply a function to elements of multiple lists simultaneously.
Example:
# Define two lists
list1 <- list(1, 2, 3)
list2 <- list(4, 5, 6)
# Add corresponding elements of the two lists using pmap()
sum_list <- pmap(list(list1, list2), ~ ..1 + ..2)
print(sum_list)C. safely(), quietly(), and possibly()
These functions are used to handle errors and exceptions gracefully while applying a function.
safely(): Returns a list containing the result and any error encountered.quietly(): Returns a list containing the result, any warnings, and any messages.possibly(): Returns a default value if an error is encountered.
Example:
# Define a list with numbers and a character
mixed_list <- list(1, 2, "a", 3)
# Define a safely wrapped square function
safe_square <- safely(~ .x^2)
# Apply the safe_square function to the mixed_list
results <- map(mixed_list, safe_square)
print(results)D. compact() and compose()
compact() is used to remove NULL elements from a list, while compose() allows you to combine multiple functions into a single function.
Example:
# Define a list with NULL elements
null_list <- list(1, NULL, 2, NULL, 3)
# Remove NULL elements using compact()
clean_list <- compact(null_list)
print(clean_list)
# Compose two functions: square and increment
square <- function(x) x^2
increment <- function(x) x + 1
square_and_increment <- compose(increment, square)
# Apply the composed function to a number
result <- square_and_increment(3)
print(result)These core functions are just the beginning of what purrr has to offer. In the next section, we will demonstrate how to use these functions to solve real-world problems through practical examples.
Practical examples with purrr
In this section, we will explore two practical examples that demonstrate how the purrr package can be used to solve real-world problems efficiently.
A. Example 1: Calculating summary statistics for multiple variables
Suppose you have a data frame with multiple numerical variables, and you want to calculate summary statistics (mean, median, and standard deviation) for each of these variables.
# Load required packages
library(dplyr)
library(purrr)
# Create a sample data frame
data <- data.frame(
var1 = rnorm(100, mean = 10, sd = 2),
var2 = rnorm(100, mean = 20, sd = 5),
var3 = rnorm(100, mean = 30, sd = 3),
stringsAsFactors = FALSE
)
# Define a list of summary functions
summary_functions <- list(mean = mean, median = median, sd = sd)
# Calculate summary statistics for each variable using nested map functions
summary_stats <- map_dfr(summary_functions, ~ map_dfc(data, .x), .id = "Statistic")
print(summary_stats)B. Example 2: Fitting multiple linear models for different subsets of data
In this example, we will fit linear models for different subsets of the mtcars dataset based on the number of cylinders. We will use purrr functions to apply the linear model function to each subset and extract the model coefficients.
# Load required packages
library(dplyr)
library(purrr)
library(broom)
# Split the mtcars dataset by the number of cylinders
mtcars_split <- mtcars %>% group_split(cyl)
# Define a function to fit a linear model and extract coefficients
fit_lm <- function(data) {
model <- lm(mpg ~ wt, data = data)
coef <- data.frame(tidy(model)) %>%
select(term, estimate) %>%
mutate(cyl = unique(data$cyl))
return(coef)
}
# Apply the fit_lm function to each subset using map_dfr()
model_coefs <- map_dfr(mtcars_split, fit_lm)
print(model_coefs)C. Reading Multiple CSV files with purrr
Suppose you have multiple CSV files in a directory and you want to read them all into a single data frame using purrr. Here’s an example of how you can achieve this:
# Define the directory containing the CSV files
csv_directory <- "path/to/your/csv/files"
# List all CSV files in the directory
csv_files <- list.files(csv_directory, pattern = "*.csv", full.names = TRUE)
# Define a function to read a CSV file and add a column with the filename
read_csv_with_filename <- function(file) {
data <- read_csv(file)
data <- data %>% mutate(filename = basename(file))
return(data)
}
# Read all CSV files using map_dfr() and bind the results into a single data frame
combined_data <- map_dfr(csv_files, read_csv_with_filename)In this example, we first list all the CSV files in the specified directory. Then, we define a custom function read_csv_with_filename() to read each CSV file and add a column with the filename. Finally, we use purrr‘s map_dfr() function to apply the custom function to each file in the list and bind the results into a single data frame.
D. purrr and ggplot2
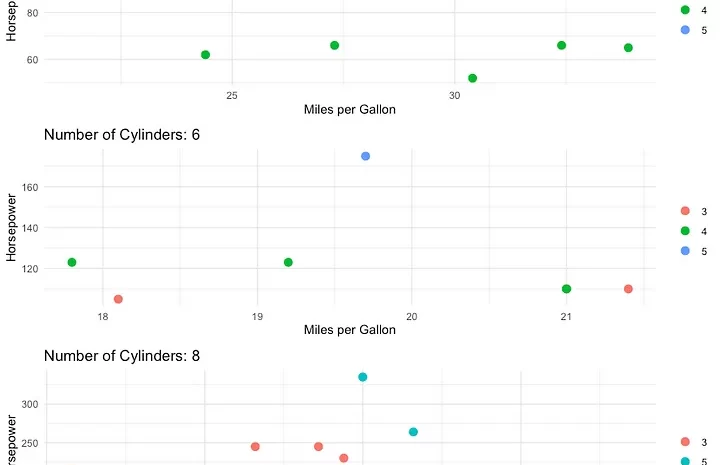
In this example, we’ll demonstrate how to use purrr to create multiple ggplots for different subsets of data within a single data frame. We’ll use the mtcars dataset and create separate ggplots for each unique number of cylinders.
# Load required packages
library(purrr)
library(ggplot2)
library(dplyr)
library(cowplot)
# Create a list of data frames, one for each unique number of cylinders in the mtcars dataset
data_list <- mtcars %>%
split(.$cyl)
# Define a function to create a ggplot for a given data frame
create_ggplot <- function(data) {
ggplot(data, aes(x = mpg, y = hp)) +
geom_point(aes(color = factor(gear)), size = 3) +
labs(title = paste("Number of Cylinders:", unique(data$cyl)),
x = "Miles per Gallon",
y = "Horsepower") +
theme_minimal() +
theme(legend.title = element_blank()) +
scale_color_discrete(name = "Gears")
}
# Create a list of ggplots using map()
ggplot_list <- data_list %>%
map(create_ggplot)
# Combine the ggplots into a single plot using cowplot's plot_grid()
combined_plot <- plot_grid(plotlist = ggplot_list, ncol = 1, align = "v", rel_heights = c(1, 1, 1))
# Display the combined plot
print(combined_plot)In this example, we first create a list of data frames, one for each unique number of cylinders in the mtcars dataset. Then, we define a custom function create_ggplot() to create a ggplot for a given data frame. The function creates a scatterplot of miles per gallon (mpg) versus horsepower (hp), with a title that reflects the number of cylinders.
Finally, we use purrr‘s map() function to apply the custom function to each data frame in the list, resulting in a list of ggplots. We use a for loop to display each ggplot.
The plot we get can be seen below:
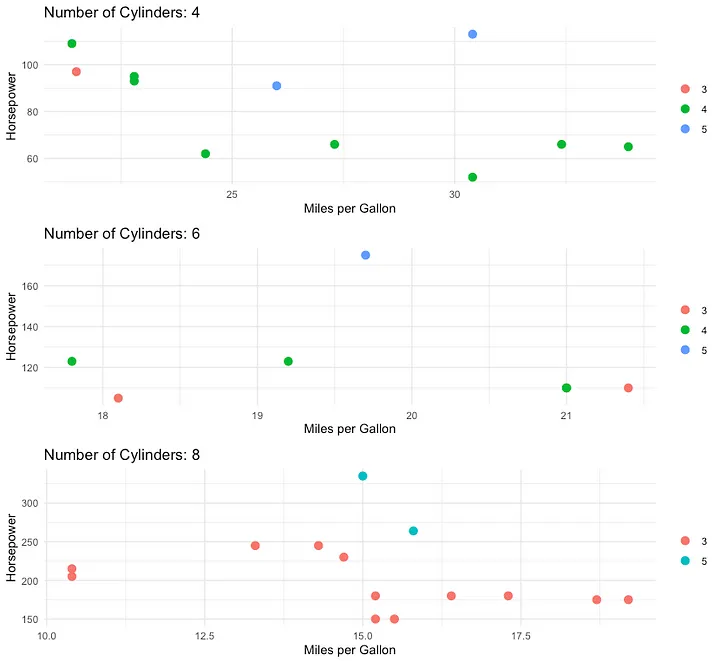
In this example, we’ve made some changes to the create_ggplot() function to improve the aesthetics of the plots:
- We use
geom_point(aes(color = factor(gear)), size = 3)to color the points by the number of gears and increase their size. - We apply
theme_minimal()to use a minimalistic theme for the plots. - We remove the legend title using
theme(legend.title = element_blank()). - We rename the color scale to “Gears” using
scale_color_discrete(name = "Gears").
Finally, we use the plot_grid() function from the cowplot package to combine the ggplots in the ggplot_list into a single plot with one column and display the combined plot.
These examples showcase how the purrr package can help you write more efficient and readable code, making your data analysis workflows more robust and maintainable. By incorporating purrr into your R projects, you can take full advantage of functional programming techniques and harness their power to solve complex problems.
Tips and Best Practices for Using purrr
In this final section, we will share some tips and best practices for using the purrr package in your R projects. These recommendations will help you write more efficient, readable, and maintainable code.
1. Use anonymous functions when appropriate
When using map() functions, you can create anonymous functions using the ~ notation, which allows for concise and readable code. However, if the function becomes too complex or is used multiple times, consider defining it as a separate named function for better code organization and readability.
2. Leverage the power of function composition
The compose() function allows you to create new functions by combining existing ones. This technique promotes code reusability and makes it easier to build complex functionality by breaking it down into simpler, more manageable parts.
3. Handle errors gracefully
When applying a function to a list or vector, use functions like safely(), quietly(), and possibly() to handle errors gracefully without stopping the execution of your code. This approach ensures that your code remains robust and can handle unexpected input values.
4. Know when to use purrr vs. base R or dplyr
While purrr provides a powerful and flexible way to manipulate data, there are cases where base R or dplyr functions may be more appropriate or efficient. For example, if you need to perform simple operations on a data frame, consider using dplyr functions like mutate() or summarize(). Evaluate the needs of your specific task and choose the best tool for the job.
5. Familiarize yourself with the purrr documentation
The purrr package has a wealth of functions and features that can help you streamline your code and solve complex problems. Make sure to consult the official documentation (https://purrr.tidyverse.org/) to explore its full capabilities and discover new techniques.
By following these tips and best practices, you can fully leverage the power of the purrr package in your R projects, making your code more efficient, readable, and maintainable. Embrace the functional programming paradigm and use purrr to solve real-world data analysis challenges with ease.
Wrapping up
Throughout this article, we’ve delved into the capabilities and adaptability of R’s purrr package in the realm of functional programming and data handling. Spanning from foundational functional programming principles to the pivotal role of the map() function suite, all the way to intricate subjects like engaging nested data sets and adept error management.
Using real-world scenarios, we’ve showcased how purrr can be instrumental in de-complicating daunting tasks, optimizing your scripts, and enhancing its legibility and sustainability. Incorporating purrr into your R utilities ensures a smoother journey through data manipulation and analytical hurdles.
As you venture further into the depths of the purrr package, bear in mind that mastery comes with repetition. Embrace exploration, and endeavor to ingeniously apply purrr functionalities in your endeavors. With perseverance, you’ll cultivate a profound grasp of its intricacies, propelling you towards proficient data management in R.
Happy coding!
Further Reading and Exploration:
For those eager to expand their expertise on purrr and R’s functional programming, consider the following treasure trove of resources:
purrr’sOfficial Guide: As a logical first step, thepurrrpackage’s official documentation provides a thorough overview of all it offers. Dive into the nuances atpurrr’sofficial site.- R for Data Science: A masterpiece penned by Hadley Wickham and Garrett Grolemund, this digital tome offers an exhaustive look into R’s role in data science. Notably, it features a segment dedicated to
purrr’sprowess in functional programming. Grab your copy here. - Advanced R: A deeper dive by Hadley Wickham, “Advanced R” ventures into the more intricate aspects of R, shedding light on advanced functional programming paradigms. Embark on this advanced journey here.
- RStudio’s Vibrant Community: Seeking advice, hoping to discuss new findings, or simply aiming to network? The RStudio community is a hub of enthusiasts, experts, and curious minds. Engage with like-minded individuals right here.
Harnessing these resources and proactively mingling with the wider R circle will undoubtedly refine your prowess with both the purrr package and R’s functional programming realm. Continue your journey of discovery, trial, and collaborative learning to blossom as an adept data scientist and R aficionado.




